Overview
This article provides details on the Technical Strategy & Plan document, which is one of the key tools / documents involved in planning a successful complex integration project.
This is the technical planning document (or documents) that specify how the data syncing mechanism (described in the Data Mapping Sheet) will actually be built (or bought & configured), deployed, taken live, and operated / supported. It is the technical plan to make the integration actually work (and deliver the results outlined in the Data Mapping Sheet).
This plan document is created by the Technical Planner as part of the overall integration strategy.
Topics Covered
This article covers the following topics:
- The Technical Strategy & Plan Overview
- Items To Factor Into Your Technical Plan
- Build or Buy (& Configure) the Sync Tool
- Getting Data To/From Each Software Application
- Initial Seeding of Data
- Knowing When to Sync The Data (When Data Changes)
- Handling Data Deletes
- Field-Level Translations / Logic
- Leverage CIMcloud Transaction Sync Monitoring
- Measuring Sync Tool Performance
- Measure Sync Tool Data Delivery Quality
- Use of Synchronous vs. Asynchronous Data Updates (specific to the CIMcloud API)
- Logging & Monitoring
Part of a Series of Articles
The article you are currently reading is part of a series of articles that are all organized and summarized in this Integration Reference Guide (Using the CIMcloud API).
Critical for Complex Integrations
The concepts presented in this article are particularly critical for complex integration projects.
Audience (for This Article)
The intended audience for this article is CIMcloud customers (and their contractors / partners) that are considering building and/or managing / supporting an integration between CIMcloud and any other software system.
The Technical Strategy & Plan Overview
This is the technical planning document (or documents) that outlines 1) the technology / tools that will be used, configured, and/or developed, 2) the testing plan that will be executed, and 3) the ongoing operations and support plan that will be needed to make the integration work (and keep it working). In short, this is the technical plan to make the integration actually work (and deliver the results outlined in the Data Mapping Sheet).
This document is created by the Technical Planner.
This document is used by the developers to complete, test, roll-out, stabilize, run, and support the integration work / sync tool.
Items To Factor Into Your Technical Plan
The following items are typically considered and solved when creating a technical strategy and plan for any complex integration project.
Build or Buy (& Configure) the Sync Tool
You will need to determine what tool you will use to actually move the data between the two systems being integrated (this is what calls the source API, translates the data, and sends it to the destination API). The Data Mapping Sheet (produced by the Solution Architect) should tell you exactly what data needs to move (down to the field level transaction logic and mapping).
There are many commercially available integration (or sync) tools that are available to move the data between two system. Some are built to install on a local network (on-premise) while others are IaaS (Integration as a Service) platforms that are run in the cloud. The are lots of additional variations / strategies as well.
Note: some software applications have sync tool style mechanisms built in (i.e. web hooks may be included) that enable the source application to format and send (post) data to a destination API based on certain conditions being met.
Getting Data To/From Each Software Application
For each table-to-table mapping in the Data Mapping Sheet, you will need to factor in the tools available to get data from the source to the destination application. This might include the use of APIs, direct access to the database, or other programming interfaces that each system has available.
Initial Seeding of Data
Part of the technical plan needs to account for the initial seeding (from the source system to the destination system) of data. Will all records or just some subset of records by synced to start (note: typically the data changes are synced from that point forward – see below).
Knowing When to Sync The Data (When Data Changes)
You will need to know when the data records that need to sync actually change (when they are added and edited). Those changes in data should trigger your sync tool to pick them up and send them to the destination application. Common methods for this include:
- Method #1: reliable add / last modified date field on records
- This applies when the source software system reliably posts a last-modified date-time on each records you want to track.
- You can program your sync tool (on each table of data you are syncing) to statically store the most recent last-modify date-time sync’d until it runs again. The sync tool can then uses that last-modify date-time on the next data pull to get all records with a last-modify date >= the date-time statically stored.
- Example, you sync tool…
- Pulls customer accounts by last_modify_date > 2/20/2022 4:45:22 PM
- It gets 27 records
- It gets (and stores) the most recent last_modify_date from those 27 records (in this case, assume it was 2/20/2022 4:51:30 PM
- It sends the 27 records to the destination system
- It stores 2/20/2022 4:51:30 PM (for use with the next run)
- On it’s next schedule run, it customer accounts by last_modify_date > 2/20/2022 4:51:30 PM
- Note: Using this technique will insure that differences in server / application clocks will not cause data change misses.
- Tip: An additional safeguard can be put in place to do an “overlap” sync once per night that pulls all records from the past 24 hours. This is an insurance policy to make sure all data syncs. If something causes a record to get missed during the all day long incremental syncs… the nightly overlap will pick it up (but still does not have to sync all records in the table).
- Method #2: SQL triggers to queue table (table + record key)
- This is a technical that can be used if the source software system runs on a SQL database that supports installing “triggers”.
- Triggers can be created to reliably log all record adds, edits, and deletes to a new / separate table that becomes the “queue” table used by your sync tool.
- That table’s schema might include the following fields:
- Primary Key
- This is the primary key of this queue / change tracking table.
- Create Date-Time
- The trigger would set this to the NOW date-time.
- Type of Change
- This could hold “add”, “edit”, or “delete”.
- Table Name
- Example, if a record was changed in the “products” table, this would have “products” in it.
- Changed Record Key
- This would hold the primary key of the record that was changed.
- Sync Status
- new – This might be set to “new” by the SQL trigger.
- in-progress – The sync tool would then pick up everything that is set to “new” and set it to “in-progress”.
- completed – Once completed (i.e. sent to the destination system), the sync tool could then set it to “completed”
- superseded – You might program your sync tool to not send the same record more than once (i.e. if it was edited 3 times between syncs) and mark the older records as superseded.
- error – You might use something like this to know that the destination system rejected the record
- Error Message
- This might hold the error message from the destination system if the destination API gives back and error message on an individual record.
- Note: This is not needed if you have a central system / way to track sync errors (and them monitor and alarm them)
- Sync Completed Date-Time
- The sync tool would set this date-time when it completes the sync.
- Note: A cleaning service could then be programmed to clean out and/or archive all sync history records that were completed .
- Note: Your sync tool could also be programmed to retry errored records (you might consider putting a Retry Count field on this table also… so it only retries 5 times for example).
- Primary Key
- Method #3: built in change tracking in ERP
- The ERP system (or other source system) may have built in change tracking that work similar to the SQL trigger method described above.
- You can plan your sync strategy once determining what those build in capabilities are.
Note: A less desirable alternative is to sync all records in a table on a time interval. We refer to this strategy as a whole-table batch update. This can be used as a last resort (if you can’t get reliable change-tracking), but will likely result in performance problems on one or both systems (because lots of records are being updated that did not actually change) and/or user experience issues (if the sync timing is slowed down… to once per day or week… to compensate for the performance issues).
Handling Data Deletes
The technical plan needs to account for records in the source system being deleted if they have already synched to the destination system. If the record is not also deleted (or disabled) in the destination system, it can create problems (because the expectation is that it should not be there). For each source table in the Data Mapping Sheet, you should indicate whether or not deletes are allowed in that table, and if so, how will the sync tool identify and communicate those deletes to the destination system.
When using the CIMcloud API, we recommend the following for deleting records in CIMcloud.
- Expired / No Longer Valid
- This applies if the record was valid at one time but has expired or is no longer valid.
- Recommended Approach = Disable the record (typically by setting the “status” field = 0)
- This will maintain data relationships on transactions or other data records that are related to / mapped to that record, but still prevent the record from being used or seen by users of CIMcloud (customers or workers).
- Mistake / Was Never Valid
- This applies if the record was sent in error and was never a valid record.
- Recommended Approach = Actually delete the record in CIMcloud.
- Note: Some CIMcloud “DELETE” resources prevent hard deletes of records (for long-term data integrity purposes / to prevent orphaned relationships) and will actually perform a “disable” below the hood when you make a delete call.
Field-Level Translations / Logic
The Data Mapping Sheet should factor in whether data can safely directly copy from the source software to the destination software without needing manipulation, or if some manipulation / special logic is needed.
- Example 1: No manipulation needed
- Company Name (in source) = text up to 150 characters
- Company Name (in destination) = text up to 200 characters
- Likely Result = The sync tool can just copy the source data to the destination data without manipulation of special logic.
- Example 2: Field size in destination is smaller than source
- Company Name (in source) = text up to 200 characters
- Company Name (in destination) = text up to 150 characters
- Likely Result = You will need to understand the behavior of the destination API (if you pass a company name over 150 characters) – will it error or truncate the data? If it errors, the sync tool will need to truncate any company names that are over 150 characters (so they fit into the destination field) before passing them to the API.
- Note: The Solution Architect would also need to be involved in this (typically this would be addressed during the Data Mapping Sheet creation on the field-to-field mappings for each sync) to determine if 1) the source software even has company names over 150 characters, 2) truncating the company name is acceptable from a business standpoint, and/or 3) the business wants to edit all company names that are over 150 characters to get them under 150 characters (so both systems will match exactly).
- Example 3: Source data is inconsistent, destination data has rigid requirement
- This example shows two common issues that come up (and need to be addressed)
- Issue #1: The source data field is free-form AND inconsistently entered
- Issue #2: The destination data field has a pre-determined list of acceptable values
- Address Country (in source) = uses typed in country names that are inconsistently entered (i.e. it contains a range of values like “United States”, “US”, “USA”, and “United State” – a typo)
- Company Name (in destination) = requires and uses ISO3 country codes (i.e. “USA”, “CAN”, etc).
- Likely Result = The data will need to be cleaned up in the source system (plus some sort of validation to prevent more messes in the future) and/or the sync tool will need to translate all possible variations into the equivalent ISO3 country code.
- Note: The Solution Architect would also need to be involved in this (typically this would be addressed during the Data Mapping Sheet creation on the field-to-field mappings for each sync) to determine if 1) the source data can be cleaned up to use the ISO3 country code, 2) the source data can be cleaned up to use consistent country names (so the translation work in the sync tool is easier), 3) the source data cleanup can / should be supplemented with code changes to the source software to force compliance of the new cleaned up countries, 4) the sync tool code should just account for all known variations and translate them, and/or 5) what is going to happen if a new country variation is introduced in the source data that the sync tool does not translate (how will that be identified and corrected)?
- This example shows two common issues that come up (and need to be addressed)
Leverage CIMcloud Transaction Sync Monitoring
Note: This applies if you are providing your own ERP sync tool to sync CIMcloud with your ERP system (vs. using a CIMcloud standard connector or pro-services assisted connector).
When syncing online transactions (i.e. orders, invoice payments, returns, etc) or other data changes from CIMcloud into your ERP system, you can leverage a built in tracking, monitoring and alarming system (that CIMcloud uses with our standard ERP connector packages) to help insure your sync tool is running successfully.
CIMcloud uses a common strategy for our monitoring and alarming. The below example and explanation provide an overview of how it works.
Example (and Explanation):
To make the explanation easier, we will use online orders placed on CIMcloud as an example (but this applied to other tables / transactions as well).
- Fields are included on the order header table to track the following:
- Exported? (field name = exported)
- Expected values: 0, 1 (blank or null = 0)
- Import Status (field name = erp_import_status)
- Expected values: pending, success, failed (blank or null = pending)
- Import Error Message (field name = erp_import_error)
- Expected value: {error message preventing order from importing successfully}
- Exported? (field name = exported)
- When pulling new orders from the CIMcloud API, it will automatically pull all orders with exported < > 1
- The API endpoint will then automatically set exported = 1 on all records pulled
The Worker Portal allows your workers to track what is happening, and potentially help resolve issues if they occur.
- The Manage Online Orders page shows these fields.
- click the image to enlarge
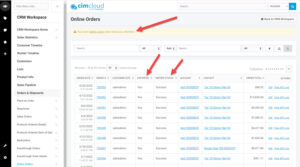
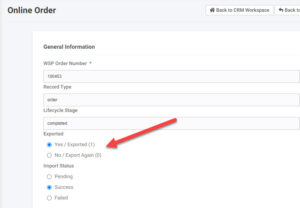
- Workers can reset the “exported” flag to cause the sync tool to pick it up again
- Tip: Be sure you sync tool will not duplicate orders (it should be programmed to prevent duplicates by looking at the order number).
- click the image to enlarge
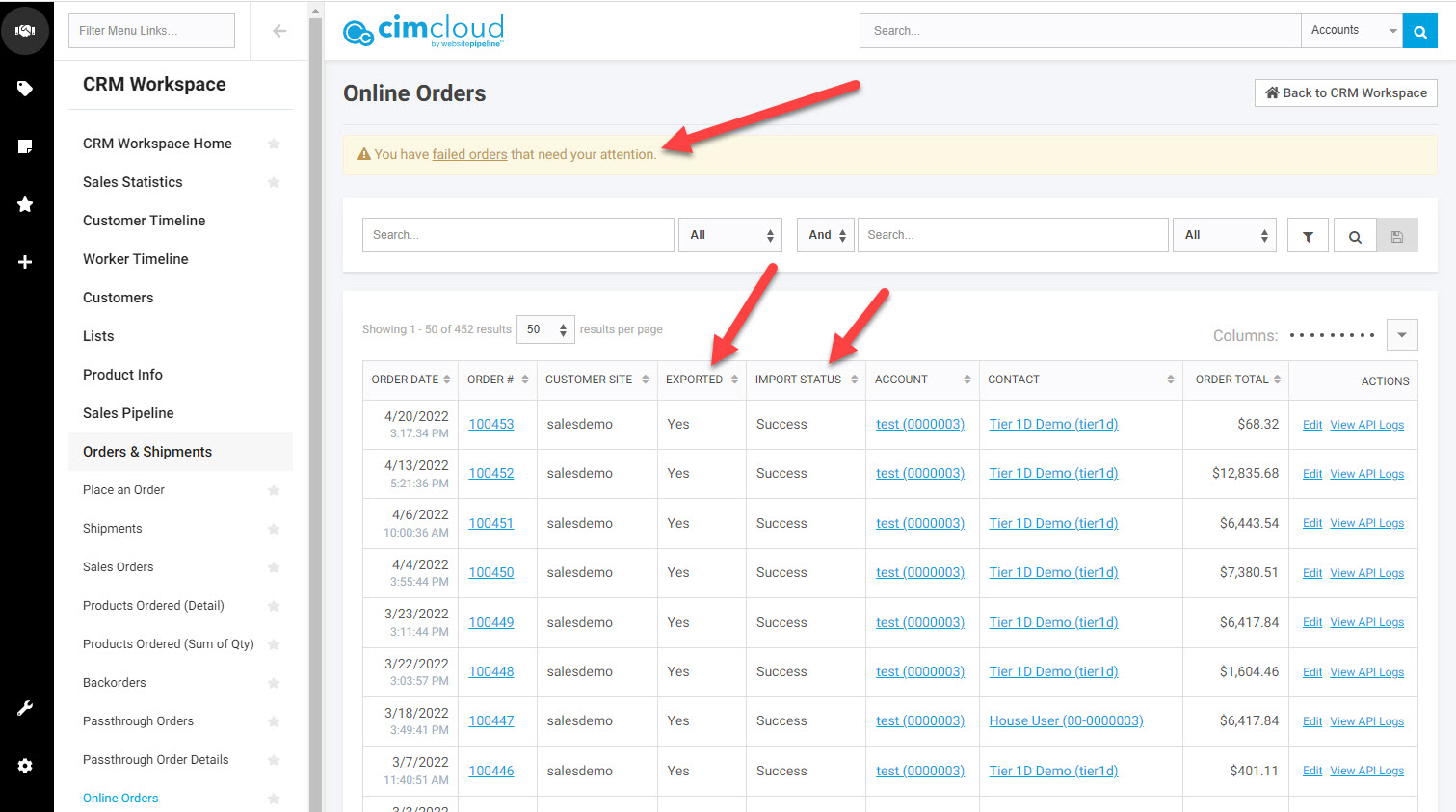

The Monitoring System built into CIMcloud has monitors (already built) that you can turn on use, including:
- A monitor that emails you if the sync tool was late picking up new orders.
- A monitor that emails you if an order failed on import.
- This includes the error message (posted back by your sync tool) so the worker can route the issue or take corrective actions.
- Example: If the order failed to import because the zip code used on the order’s ship to address did not match a valid zip code in the ERP system (some ERP’s validate this), the zip code could be edited by the worked in the CIMcloud Worker Portal and then reexported (by setting the exported flag back to “No / Export Again” as seen above.
Measuring Sync Tool Performance
The foundation of reliable data syncing is making sure the sync tool is running on-time with no errors. The technical plan should consider how this will be monitored (to know if issues are occurring), alarmed (to notify an operator if an issue has occurred so they can address it), and operated (the person or team responsible for making sure the service is running).
The performance can be measured primarily by knowing these three things:
- Did it start the run on time / with-in an acceptable tolerance of the scheduled next run time?
- If it runs every 5 minutes, you might expect it to start with-in 1 minute of the run time.
- Did it complete the sync with-in an acceptable time window?
- If it runs every 5 minutes, you might expect to complete in 2 minutes.
- It it is taking 2 hours to run, you will need to speed up the performance or change your run frequency and expectation level of when the sync performs.
- Did it complete the work without (silent) erroring?
- The goal is to make sure silent errors aren’t showing as successful runs when the tool didn’t actually do it’s job.
- If the source or destination systems (i.e. their API’s) throw an error and the sync tool collected and reported the error on-time…. this falls into a separate category of issues than pure sync tool running / performance (i.e. the source or destination system may have an issue that needs to be addressed).
Measure Sync Tool Data Delivery Quality
This goes beyond performance and is looking at the results of the data syncing from a business / user standpoint to make sure the data that landed in the destination system matches expectations. For example, if you are syncing open invoice data from your ERP system to a customer self-service portal, the open invoice balances must be correct. This could be measured by looking at the total open AR balance per customers in the portal and comparing it to the total open AR balance in the ERP system. If they match on all customers, that tells you that you likely do not have a quality or performance problem.
Use of Synchronous vs. Asynchronous Data Updates (specific to the CIMcloud API)
The CIMcloud API allows for either 1) synchronous updates (immediately commits changes to the database up to 10 records at a time) or 2) asynchronous updates (receives a batch of records, drops them into a message queue, and asynchronously updates them to the database and logs the response). There are benefits and tradeoffs to both options that you can consider (and then decide on) when planning your technical strategy.
More details on how the CIMcloud uses Asynchronous vs. Synchronous updates are included in the API Framework Overview article (which is more technical in nature).
Logging & Monitoring
Part of your technical plan should consider how you will log and monitor the data syncing to make sure what you expect to happen is actually happening. This should include what data / logging you want to capture and retain, how long and where you will retain it, how you will monitor it to alert an operator if issues are occurring that need human intervention, and who will be the human (operator) that intervenes if there is an issue. Note: In addition to active monitoring, the logs are useful for technical trouble-shooting and studying performance trends.